
오늘부터 SQL 팀 프로젝트로 데이터를 통해 인사이트 도출하고 가설 검증까지 하는
EDA(탐색적 분석)해보도록 하겠습니당.
우선 데이터 분석에 앞서 데이터를 불러오도록 하겠습니다.
오늘의 데이터는 공공데이터로 서울시 따릉이 자전거 데이터를 사용하겠습니다.
데이터가 너무 커서 압축 파일로 올리려했으나 압축 파일도 너무 커서 데이터를 다운 받을 수 있는 링크를 공유드릴게요
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr

위 링크에서 사용하는 4개의 데이터 셋입니다.
지난 시간 DBeaver 에서 데이터를 불러오기 했는데
큰 데이터 가져오는것은 달라서 다른 방법으로
불러와야한다....
📌DBeaver에서 데이터 불러오기
Table > 데이터 가져오기

input file에서 파일 선택 후 > 하단 Trim whitespaces 로 앞 뒤 공백을 지워줍니다. (생략 가능)

> Tables mapping 에서 테이블 명과 target Type을 바꿔줍니다.
(안그러면 에러나서 데이터를 못 불러옴 ㅜㅜ )
* 저는 데이터를 처음 불러오는거라 Target Type을 다 VARCHAR(200)으로 바꿔줬습니다.

⬇️ import 잘된 데이터 셋

📌테이블명 & 컬럼명 바꿔주기
가져온 데이터는 모두다 한글로 되어있기에 혹시나 SQL 쿼리를 짜면서 오류가 생길수 있기에
모두 영문으로 바꿔주는 작업을 합니다.
| Table 명 | 바꾼 Tabel 명 |
| 서울시 공공자전거 고장신고 내역 | trouble_list |
| 서울시 공공자전거 대여소 정보 | rental_info_list |
| 서울시 공공자전거 이용정보(일별) | use_list |
| 서울시 공공자전거 대여이력 정보 | rent_list |
*사실 컬럼명도 다 바꿔주었는데 너무 많아서 생략하겠숨당...
📌데이터값 확인 (count)
모든 데이터들은 count 함수로 불러와서 데이터가 잘못 불러온것이 없는지 확인
SELECT count(*)
from use_list -- (rent_list),(trouble_list), (rental_info_list)
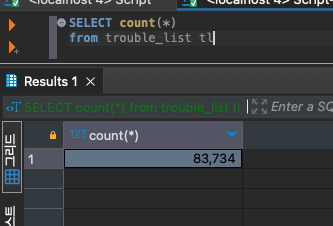

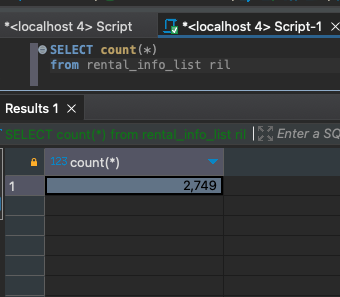
데이터는 모두 잘 불러와졌고 250만개의 데이터라니 어마어마하다.
📌데이터 NULL 값 확인(IS NULL)
테이블마다 NULL값이 다르기에 한개씩 맡아서 진행
나는 rental_info_list를 맡았고 null 값은 아래와 같이 구했다.
컬럼명 하나씩 대입해서 숫자가 다른지 확인햇다.
SELECT count(rental_num),count(reated_icd_cnt)
from rental_info_list ril;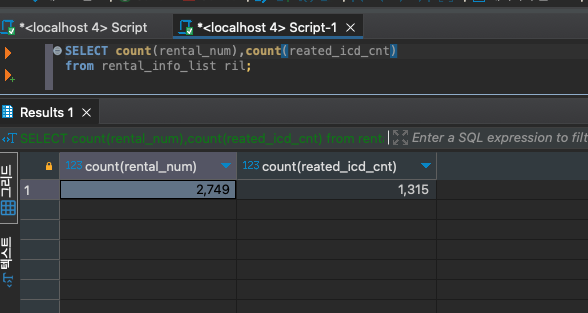
어라라? 숫자가 다르네 NULL 값이 있나보다!
하지만 NULL값으로 조회했을때는 나오지 않는다 왜지? (아시는분 알려주소서,,)
SELECT count(reated_icd_cnt)
from rental_info_list ril
where reated_icd_cnt IS NULL ;
SELECT count(created_qr_cnt)
from rental_info_list ril
where created_qr_cnt !="";
요렇게 != 하면 나오는데
IS NULL에도 안나오는 너란 NULL 값,,,,
📌중복 데이터 확인(DISTINCT)
📍rent_list 에 있는 데이터중에서 중복 값이 있거나 특이한 값에 대해 분류해보자.

1. 중복값 제거후 확인
SELECT count(DISTINCT bike_id) -- 'bike_id' 말고 다른 컬럼명을 넣어도됨
from rent_list;
2. 날짜 별로 분류
날짜는 rent_dt 로 SUBSTR을 사용해서 분리해줬다.
처음 년도 > 월별 > 일별 순으로 데이터를 조회하니 분리가 되지 않아서 일별로 조회하니 값이 나왔다.
SELECT SUBSTR(rent_dt,2, 9) as day, count(rent_rental_num)
from rent_list
group by day;
3. 분류하기
SELECT rental_rests, COUNT(rental_rests)
from rent_list
group by rental_rests
order by rental_rests
SELECT use_type,count(use_type)
from rent_list
group by use_type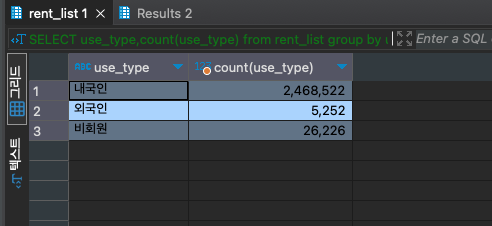
📍use_list
연령대별 고객 리스트를 분류해보자.(age)
SELECT DISTINCT age, count(age)
from use_list
group by age;
이용자별 횟수를 분류해보자 (use_num)
SELECT DISTINCT min(use_num), max(use_num)
from use_list

🚨 분명 100넘는 값이 있는 줄알았는데 min, max로 구하면 98이 max 값으로나온다 왜지? (향목님 여쭤보기)
SELECT use_num, max(use_num), count(use_num)
from use_list
-- where use_num >= 100;
group by use_num
order by count(use_num) DESC;

📍rental_info_list
에 있는 데이터중에서 중복 값이 있거나 특이한 값에 대해 분류해보자.
하나씩 매칭해본후 중복값이 있는 것을 자세히 조회했다.
1. rental_name
처음 데이터의 중복이 있는지 확인하려면
SELECT rental_name, CHAR_LENGTH(rental_name), count(rental_num) as total
from rental_info_list
group by rental_name
HAVING total > 1
2개씩 있는 데이터가 보여서 하나씩 세부정보를 보면서 같은 정류소인지 확인했다.
SELECT *
from rental_info_list
WHERE rental_name = "한양수자인아파트 앞"
SELECT *
from rental_info_list
WHERE rental_name = "천왕이펜하우스5단지 앞"
SELECT *
from rental_info_list
WHERE rental_name = "국회3문";


3개 모두 다른 데이터로 rental_name은 같지만 detail_address 와 위도 경도가 다르니 이름만 같은 다른 정류소라 할 수 있다.
그럼 detail_address 같은 데이터가 더 있나 확인해보자.
SELECT detail_address, count(detail_address), count(rental_name), count(rental_num)
from rental_info_list
group by detail_address
having COUNT(detail_address) > 1
order by count(detail_address) desc;
총 67개의 동일한 주소가 있었다. 우선 하나씩 보면 왜 같은 detail_address인지 확인할 수 있다.
가장 많은 detail_address 를 갖고있는 "국회의사당 경내"의 데이터를 확인해봤다.
SELECT *
from rental_info_list
where detail_address ="국회의사당 경내";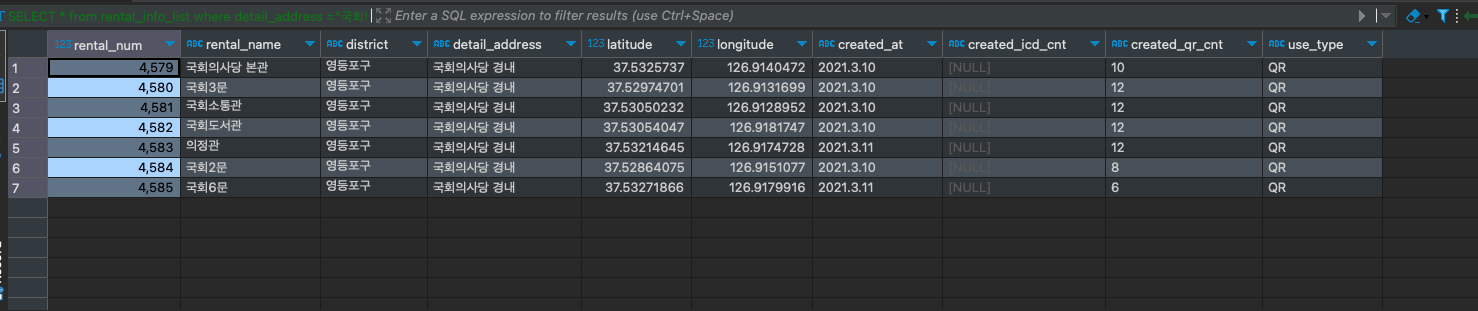
주소가 같아도 rental_num, latitude,longitude 가 다르니 다른 데이터라고 할 수 있다.
그렇다면 latitude, longitude가 같은 것도 있을까? 중복데이터를 확인해보자
SELECT COUNT(DISTINCT latitude), COUNT(distinct longitude)
from rental_info_list
group by longitude,latitude
having COUNT(latitude) > 1;
다행히 중복데이터는 없는것으로 보인다.
2. 어떤 구에 몇 개의 거치소가 있는지 확인
SELECT district, count(district)
from rental_info_list ril
group by district
order by count(district) desc
📍trouble_list
마지막으로 확인해볼 데이터는 고장 신고 데이터다 컬럼이 짧아서 확인할게 적다.
SELECT trouble_type, count(trouble_type)
from trouble_list
group by trouble_type
order by count(trouble_type) DESC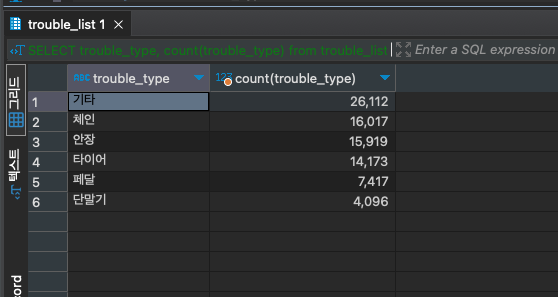
오늘 SQL로 데이터를 제대로 만져보는게 처음인거 같은데 나름 이것저것 다 넣어보고 원하는 결과값이 나오는게 신기했다.
다만 아직 group by 나 select 절에 집계함수 사용하는법을 자주 까먹어서 잊어버리지 않고 꼭 써주는 것이 중요할듯!
데이터 종류도 많고 이상치도 꽤 있는것 같아서 다뤄보기 재밌을거 같다~!
남은 팀 프로젝트도 화이팅이다!!
'성동 1기_ 모빌리티 전Z전능 DA' 카테고리의 다른 글
| Python 기초(1) - 아나콘다 설치, 주피터 노트북 설치, 파이썬 기초, 내장함수 (0) | 2023.11.24 |
|---|---|
| SQL 팀프로젝트 (2) - EDA 분석, NULL 값 치환, 가설 세우기 (1) | 2023.11.22 |
| SQL 다시보기2. JOIN/GROUP BY/ DISTINCT/ HAVING활용하기 (0) | 2023.11.16 |
| DAY 23 - 스타트업 vs 대기업 / SQL 짝코딩 (0) | 2023.11.15 |
| DAY 21 - 마케팅 데이터 분석 (마케팅 데이터 리터러시) (1) | 2023.11.15 |